Após a familiarização com o uso do sistema GNU/Linux por meio da interface gráfica dada na primeira aula deste curso, buscaremos agora entender um pouco do que se trata um sistema operacional GNU/Linux, como ele é organizado, quais suas responsabilidades e como interagir com ele utilizando a linha de comando, o que possibilita utilizar um conjunto muito mais amplo de ferramentas.
Nosso roteiro completo é o seguinte.
- Um pouco de história
- O que é um Sistema Operacional?
- Organização da estrutura de diretórios
- Utilizando a linha de comando
Um pouco de história
Por ser o produto de um desenvolvimento colaborativo e livre, a história do Linux pode ser bastante confusa de se entender à primeira vista. O Linux surge a partir de uma reinterpretação do Minix, um sistema operacional (SO) baseado em Unix, por Linus Torvalds, reconhecido como o principal desenvolvedor e criador do Linux. Torvalds utilizava o SO Minix e, em 1991, começou a trabalhar em algumas ideias de um SO baseado em Unix, apesar disso, o resultado divergiu bastante do produto em qual foi inspirado.
Por sua vez, o Unix surge a partir de uma ramificação de um projeto chamado Multics, um SO que estava sendo desenvolvido por grandes empresas, como a Bell Labs, General Electrics e até mesmo o Instituto de Tecnologia de Massachusetts, mas que estava apresentando uma complexidade e tamanho exagerados. Por conta disso, alguns pesquisadores dessas empresas, lentamente, afastaram-se do desenvolvimento do Multics e começaram um novo projeto de escala menor, o Unics, que posteriormente passou a ser chamado de Unix (ninguém envolvido na época lembra como esse nome surgiu).
Com o nascimento do kernel Linux, diversos desenvolvedores foram capazes de construir seus próprios sistemas operacionais, como por exemplo a distribuição Ubuntu, que foi construída sobre a arquitetura e a infraestrutura do Debian, um outro SO que utiliza o kernel Linux. Grande parte dos SO baseados em Linux hoje em dia também seguem a licença pública geral (GNU), um conjunto de diversos softwares livres que podem ser utilizados e seguem a filosofia das quatro liberdades, visando garantir ao usuário a liberdade de usar, estudar, modificar e redistribuir os softwares inclusos.
O que é um Sistema Operacional?
Embora falemos costumeiramente sobre Sistemas Operacionais (SO) — por exemplo, Ubuntu, Debian, Fedora, MacOS (e até mesmo, por mais incrível que pareça, o Windows) —, dificilmente nos perguntamos porquê ele é necessário e quais são suas responsabilidades.
Para responder o que é um SO, vamos primeiro considerar um cenário hipotético em que somente existem aplicações para o usuário final sendo executadas na máquina, por exemplo, o navegador que você está utilizando neste momento. Neste caso, os desenvolvedores do navegador precisariam saber como exatamente enviar comandos e interpretar as respostas dadas por todo o seu hardware. Por exemplo, seria necessário saber quais são as instruções implementadas no processador específico de sua máquina, sua webcam, seu disco rígido, como utilizar a CPU e memória em conjunto com outras aplicações que estão rodando simultaneamente na sua máquina e diversos outros aspectos.
Não é difícil de ver que desenvolver qualquer aplicação com o mínimo de qualidade em uma situação dessas é extremamente difícil (senão impossível). Para piorar a situação, não poderíamos garantir o mínimo de segurança, já que qualquer aplicação teria a permissão para manipular todo o sistema e o seu hardware diretamente!
Assim, conseguimos ver a necessidade de um mecanismo para resolver esses problemas. O sistema que objetiva lidar eles (e muito outros) é justamente o Sistema Operacional. Dada a tamanha complexidade dessa tarefa, os sistemas operacionais que utilizamos em nosso dia-a-dia (como o Ubuntu), podem ser divididos em diferentes níveis, cada um dos quais tem suas responsabilidades. O primeiro nível e mais importante é o kernel, que vamos discutir na sequência.
O kernel
O kernel (em português, núcleo), como seu próprio nome diz, é a parte fundamental de um SO. Ele é responsável basicamente, por lidar com a interação direta com o hardware do dispositivo, o que inclui a unidade central de processamento (CPU), memória RAM, dispositivo de armazenamento (por exemplo, disco rígido) e outros dispositivos de entrada e saída. Consequentemente, qualquer aplicação em execução (também chamada de processo) que necessite, por exemplo, de mais memória deve solicitar ao kernel, que por sua vez verificará qual região da memória física pode ser designada ao processo.
Assim, algumas das grandes tarefas a serem desempenhadas pelo kernel são:
- Virtualizar a CPU. O objetivo é fazer com que os processos consigam utilizar a CPU alternadamente de uma forma justa e segura, mas sem que cada um deles saiba que isso está acontecendo.
- Virtualizar a memória. Aqui o objetivo é parecido com o anterior, mas com a alocação de memória, de forma que o processo veja como se uma memória (menor do que a real) estivesse toda disponível ao processo. Isso possibilita mecanismos muito úteis, como o uso disco rígido como “extensão” da memória RAM (o chamado swapping).
- Gerenciar o sistema de arquivos em disco. Diferente dos anteriores, aqui não é possível simplesmente deixar os processos verem ao que foi gerado por si mesmos, já que os dados do usuário deveriam pode ser manipulados por diferentes aplicações, por exemplo um editor de texto e um explorador de arquivos. Assim, o kernel fica responsável por gerenciar o acesso aos arquivos seguindo as permissões atribuídas a eles, além de efetivamente decidir onde os metadados e dados dos arquivos são salvos no disco.
- Implementar drivers. Como o kernel é responsável pela manipulação do hardware, todo tipo de dispositivo que se deseja ser capaz de interagir necessita da implementação do protocolo de comunicação específico. Isso faz com que a maior parte do kernel possa ser na realidade de drivers!
- Prover segurança. Como vimos nos itens anteriores, a segurança permeia todas as tarefas que o kernel desempenha e é uma de suas grandes responsabilidades.
Um dos kernels mais conhecidos é o Linux! Dizemos, então, que um sistema operacional é baseado em Linux quando ele utiliza o kernel Linux.
uname --kernel-name --kernel-release, que veremos mais adiante nesta aula.
Shell: interagindo com o kernel
Até o momento, comentamos o que é o kernel e suas responsabilidades. Porém, naturalmente surge uma questão: como interagir com ele?
A forma de solicitar algo ao kernel do sistema operacional é por meio de chamadas de sistema (system calls, em inglês). Essas chamadas são instruções especiais da CPU, isto é uma instrução em linguagem de montagem (assembly, em inglês), que passam o controle para o kernel com alguma solicitação — por exemplo, abrir determinado arquivo — e depois retorna o controle para o programa solicitante quando o resultado está pronto. Esse tipo de interação, como ser notado, é bem programática.
Assim, existe um outro nível do sistema operacional é que responsável por prover uma interface mais fácil de ser utilizada para realizar solicitações ao kernel. Essa interface é chamada de shell (casca, em português). Note que a terminologia é bem intuitiva, como ilustrado pela figura a seguir.
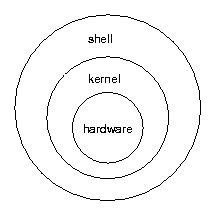
A shell pode ser visual ou por linha da comando (isto é, texto puro). Em linha de comando, como o próprio nome sugere, digitamos comandos que são interpretados pela shell e executados com ajuda do kernel.
Existem diferentes implementações de shells para sistemas Unix (como o Linux e MacOS). Algumas delas são as seguintes:
sh(Bourne Shell). Essa shell possui funcionalidades mais básicas e vem nos sistemas GNU/Linux por questão de retrocompatibilidade principalmente.bash(Bourne Again Shell). É uma versão aprimorada da Bourne Shell. Está é a shell padrão dos sistemas GNU/Linux e a que vamos discutir em maiores detalhes parte final desta aula.zsh(Z Shell). Também é uma aprimoramento da Bourne Shell, com aprimoramentos para o uso interativo.fish(Fish Shell). Diferente das últimas duas, esta shell foi escrita sem basear em outras.
Distros: complementando o kernel
Como podemos ver, mesmo com a ajuda da shell, ainda faltam componentes para um sistema operacional pareça com o que interagimos usualmente. Todos os componentes que são essenciais para o usuário final, mas não são providos kernel nem pela shell por linha de comando, são incluídos em distribuições GNU/Linux (ou também chamadas de distros, para os mais íntimos), como as discutidas no início da aula. Alguns desses componentes são os seguintes:
- Sistema de inicialização (init system, em inglês). Esse é o primeiro
processo a ser criado no sistema na fase de carregamento (boot) e é
responsável por iniciar outros programas, incluindo o que disponibilizará o
sistema de login do usuário. O sistema de inicialização mais utilizado
atualmente nas principais distribuições GNU/Linux é o
systemd. - Backend de áudio e vídeo. É responsável prover, consumir e processar dados de mídia (áudio e vídeo) para os processos em execução. Um exemplo é o PipeWire.
- Servidor de Display. É responsável pela coordenação das entradas e saídas das aplicações por uma interface gráfica, o que possibilita, por exemplo, que possamos utilizar mouse para referenciar itens na tela e que tenhamos um gerenciador de janelas de aplicações. No Ubuntu 22.04, está utilizando um servidor de display baseado no Wayland. Porém o servidor legado X.org também está disponível para ser ativado.
- Ambiente Desktop. É o que define diversos componentes visuais (como botões, menus, ícones) da interface do desktop. Por padrão, o Ubuntu e Fedora atualmente utilizam o ambiente GNOME. Outros ambientes populares são Xfce e KDE’s Plasma.
- Aplicações do dia-a-dia. As distribuições geralmente incluem por padrão algumas aplicações úteis ao dia-a-dia, como tocadores de música e vídeo, leitor de PDF, navegador, entre diversos outros.
Esquematicamente, podemos organizar esses módulos relacionados a aplicações gráficas como mostrado na figura a seguir (incluindo também o kernel e utilitários do sistema vistos anteriormente).

Essa pilha de componentes é chamada, naturalmente, de Stack do Desktop Linux.
Organização da estrutura de diretórios
Como vimos, um sistema de arquivos tem um papel importante nas responsabilidades do sistema operacional. Porém, como os dados são organizados nele?
Basicamente, duas grandes abstrações existem para organizar dados em um disco: arquivos e diretórios (também chamados de pastas). Arquivos contém literalmente os dados que estamos interessados e metadados, como o nome e as permissões. Os diretórios basicamente são representações que contém arquivos ou outros (sub)diretórios. Dessa forma, temos o que chamamos de árvore de diretórios, como ilustrada abaixo.
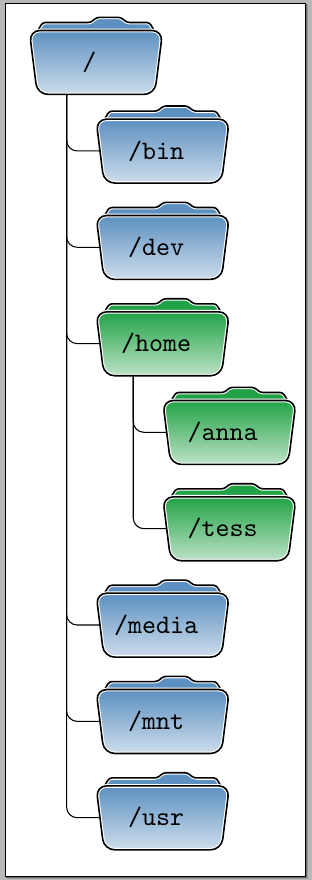
A raiz (vértice inicial) dessa árvore é designado por / no Linux. Para nos
referir a um arquivo ou diretório, adicionamos seu nome da sequência, por
exemplo /arquivo.txt. Entre nomes de diretórios e arquivos, utilizamos
novamente uma barra /, como em /home/anna/test.txt. Utilizando essa idea, é
possível indicar qualquer arquivo na árvore de diretórios.
No caso do Linux (e outros sistemas), é seguida uma convenção para a organização dos diretórios da raiz do sistema. Basicamente, os principais diretórios mais comuns de interagirmos no dia-a-dia são os seguintes:
/bin: Contém utilitários essenciais, como obash;/home: Contém os dados dos usuários;/media: Ponto de montagem de dispositivos removíveis, como pen-drives;/mnt: Ponto de montagem para outros sistemas de arquivo, por exemplo, de um outro disco rígido;/tmp: Local para arquivos temporários. Por padrão, esse diretório é completamente apagado após reiniciar o sistema./usr: Uma hierarquia secundária;/usr/bin: Contém a maior parte de programas (em binário);/usr/lib: Contém as bibliotecas dos programas;
Os outros diretórios seguem a seguinte linha de raciocínio.
/boot: Contém arquivos estático do inicializador do sistema;/dev: Contém arquivos que representam os dispositivos da máquina, como a CPU, incluindo dispositivos especiais como ozeroe onull;/etc: Possui configurações de sistema;/lib: Inclui as bibliotecas compartilhadas e outros módulos do kernel;/opt: Pacotes de aplicações adicionais ao sistema, normalmente a serem utilizadas pelo usuário final, como um navegador;/proc: Contém informações dos processos e do sistema/root: Contém a home do usuário root./sbin: Binários essenciais do sistema, alguns dos quais veremos mais adiante./srv: Local para armazenamento dos dados de serviços oferecidos pelo sistema. Normalmente, não é utilizado em um ambiente Desktop;/usr/sbin: Binários do sistema que não são essenciais;/usr/include: Cabeçalhos de programas C;/usr/share: Outros dados somente de leitura independente de arquitetura da CPU, como os manuais dos programas;/var: Local para as aplicações armazenarem dados variáveis;
Para uma explicação mais detalhada dessa convenção, veja o documento completo do padrão.
Utilizando a linha de comando
Programas de linha de comando, como o shell, são interpretadores interativos
de uma linguagem. Basicamente, o texto inserido no console é lido (até um
caractere de fim-de-linha, inserido pela tecla Enter), é interpretado como um
comando e é executado na hora, gerado uma potencial saída de texto. Para aqueles
familiarizados com Python, o console interativo do Python é um exemplo de
programa por linha de comando.
Para ver isso funcionando, vamos abrir um terminal, que pode ser iniciado na
visão das atividades (como vimos na última aula) ou pelo atalho Ctrl + Alt + t. Como dito anteriormente, estamos considerando a execução no Ubuntu,
portanto, a shell que estaremos interagindo é a Bourne Again Shell, ou
simplesmente bash para facilitar.
Você verá uma linha escrito algo como
username@hostname:~$A primeira parte é o nome de usuário que você deu durante a instalação do
sistema. Como o Linux é um sistema multiusuário, essa informação é importante
para sabermos qual usuário estamos utilizando na linha de comando. Na sequência,
parece o nome da máquina que você está, com o separador @ entre eles. O @ é
lido em inglês como at, ou seja, “em” no português. Portanto, podemos entender
literalmente como “tal usuário na máquina tal”. Após essa parte, temos mais um
separador, o : (dois pontos), seguido do caminho atual na árvore do sistema de
arquivos. Por padrão, o terminal é iniciado com a bash na sua pasta de usuário
(~). Por fim, temos um caractere ($) que simboliza o fim dessas informações
e o início do comando atual a ser executado (que está vazio no momento).
Para aquecer, vamos ver o resultado daquele comando que vimos na Seção sobre o kernel, que mostra a versão do kernel sendo utilizada em nossa máquina. Para isso, digite o comando
username@hostname:~$ uname --kernel-name --kernel-releasee pressione Enter. Uma saída parecida com
Linux 5.13.0-44-genericaparecerá na tela logo abaixo do comando.
Vamos agora dar uma olhada mais de perto no comando executado. Vemos que ele tem
um nome (uname) e é seguido por o que chamamos de argumentos (--kernel-name
e --kernel-release). A ideia é muito parecida com a de funções em linguagens
de programação, sendo neste caso o uso do -- um indicativo que o termo que se
segue é o nome de um parâmetro do programa. Neste caso, não é passado nenhum
valor explícito ao parâmetro, o que significa que ele deve ser interpretado como
verdadeiro ou ativado.
Geralmente, existem alternativas mais curtas para ativar determinados
parâmetros, de forma que o uso da linha de comando seja mais ágil. No caso do
uname, o argumento --kernel-name pode ser substituído por -s e
--kernel-release por -r, resultando no comando
username@hostname:~$ uname -s -rPodemos reduzir ainda mais o número de comandos concatenando todos os caracteres
de argumentos reduzidos (que começam com somente um -), ficando com o comando
resultante
username@hostname:~$ uname -srAntes de continuar explorando alguns comandos mais comuns, vamos ver alguns atalhos úteis do bash e como buscar ajuda para descobrir como funcionam os comandos e seus parâmetros.
Alguns atalhos do bash
Um ponto muito importante é que o bash também provê algumas funcionalidades
para facilitar ainda mais nossa vida. Por exemplo, podemos começar a digitar um
determinado comando e pressionar Tab para realizar um completamento
automático. Caso o comando atual seja ambíguo, podemos ainda precisar mais uma
vez e receber uma lista de sugestões dos comando que atualmente batem com o
escrito.
Outro ponto importante é a possibilidade de não digitar os comandos do zero toda vez. O bash armazena em disco um histórico dos comandos digitados. Para navegar nesse histórico, você pode utilizar as setas para baixo (↓) e para cima (↑) de seu teclado.
Outra opção muito interessante é a busca reversa, embora seja menos intuitiva de
ser utilizada em um primeiro momento. Ela pode ser ativada por meio do Ctrl + R. Nela, você digita parte de um termo que continua no comando desejado e ela
retorna a última ocorrência. Para continuar buscando acima da última ocorrência
encontrada, basta continuar pressionando Ctrl + R. Uma vez encontrado
resultado desejado, basta pressionar Enter para executar o comando ou seta
para a direita (→) ou (←) para editar o comando atual.
Em alguns momentos, podemos querer desistir da execução de algum comando. O
bash possui o atalho Ctrl + C justamente para mandar esse sinal ao programa
sendo executado atualmente. Ele também serve para desistir do comando digitado
até o momento, devolvendo a linha de comando limpa novamente. Por outro lado,
para limpar a tela toda e voltar a ter a linha de comando no topo, podemos usar
Ctrl + L.
Diversos outros atalhos existem o podem vir a ser úteis em algum momento. Para descobri-los, vamos agora aprender como buscar ajuda.
Buscando ajuda
Uma convenção utilizada para os programas a serem utilizados na linha de comando
é ter um argumento chamado --help que dá um resumo da funcionalidade do
programa e dos seus argumentos. Em alguns programas, o argumento pode aparecer
somente na sua forma extensa, somente na sua forma reduzida (geralmente -h) ou
em ambas. Por exemplo, no caso do uname, uma versão reduzida para a ajuda não
está disponível.
Embora o --help (ou -h) dê algumas informações sobre os argumentos, a ideia
é que ele seja uma ajuda rápida (normalmente para quando você não lembra do nome
do argumento). Para ter uma explicação do comando e de seus argumentos,
utilizamos o man (que é um encurtamento da palavra manual). A maioria dos
programas que vamos ver nas próximas seções possuem uma entrada nos manuais.
Para visualizar um manual do uname, por exemplo, basta executar o comando
username@hostname:~$ man unameEle exibirá o manual de uma forma navegável. Veja o menu de ajuda (apertando
h) fornecido por ele.
man, podemos usar… adivinhe… man man! Além disso, é possível usar saber mais sobre o bash por meio de man bash. Resumindo: está na dúvida de algo? Tente man algo.
man em outros objetos também. Por exemplo, podemos descobrir quais são as funções em uma dada biblioteca da linguagem C (por exemplo, a stdio) ou, ainda, como é a assinatura de uma determinada função.
Note que os manuais já estão disponíveis em sua máquina, de forma que não é necessário acesso à Internet para realizar uma consulta.
Navegando pelo sistema de arquivos
Também é muito comum navegar pelo seu sistema de arquivos diretamente pelo terminal.
Como já foi dito, o seu terminal deve abrir no diretório do usuário — representado
pelo símbolo ~ — e caso você precise interagir com um arquivo que está em outro
diretório, saber navegar pelos seus arquivos é essencial! Comentaremos todos os comandos
que consideramos úteis, falando sobre sua função, alguns detalhes e dicas.
. ou .. em alguns comandos porque eles representam diretórios. . representa o diretório onde você se encontra. .. representa o diretório acima do diretório onde você se encontra — caso exista —, chamado de diretório pai.
-
ls argumentos diretorioO comando
lslista os diretórios e arquivos em um determinado diretório. Caso você não forneça nenhum diretório, ele considera o diretório em que você se encontra. Seus argumentos mais utilizados são-a, que inclui diretórios e arquivos ocultos — que possuem ‘.’ no início do seu nome Ex: “.bashrc” —-l, que lista em formato de tabela e-R, que lista recursivamente cada diretório dentro desse diretório.O exemplo abaixo lista todos os arquivos em formato de tabela presentes no diretório atual.
username@hostname:~$ ls -la -
cd diretorioO comando
cd— abreviação de “change directory” — muda de um diretório para outro. Caso você esteja no diretório~e queira ir pra sua área de trabalho, basta digitarcd Desktop/. O diretório pode ser estendido indefinidamente, então se quiser acessar diretamente uma pasta chamada “pasta1” em sua área de trabalho, basta digitar, do diretório~,cd Desktop/pasta1/.O exemplo abaixo navega para o diretório pai do diretório atual.
username@hostname:~$ cd .. -
mkdir diretorioO comando
mkdir– abreviação de “make directory” — atua criando o diretório passando como parâmetro. Caso você queira criar um subdiretório junto, utilizar o argumento-pé o ideal. Usando o comandomkdir -p dir1/subdir1/, o diretório dir1/subdir1/ será criado.O exemplo abaixo cria um diretório chamado LinuxFTW no diretório padrão do usuário.
username@hostname:~$ mkdir ~/LinuxFTW/ -
rmdir diretorioO comando
rmdir– abreviação de “remove directory” — atua removendo o diretório passando como parâmetro. Porém, ele remove apenas diretórios vazios, caso você queira deletar um diretório e todo seu conteúdo, você necessita usar o comandormque será detalhado na próxima sessão.O exemplo abaixo remove um diretório chamado RuindowsFTW do diretório padrão do usuário.
username@hostname:~$ rmdir ~/RuindowsFTW/Cuidado ao utilizar os comandos rmdir e rm com o prefixosudo, alguns códigos maliciosos utilizam disso para causar grandes danos ao seu sistema. -
pushd argumentos diretorioAdiciona o diretório especificado numa pilha de diretórios, que pode ser acessada usando outros comandos abaixo, e navega até ele. Com o argumento
-na navegação não é realizada.O exemplo abaixo adiciona o diretório pai na pilha de diretórios sem navegar até ele.
username@hostname:~$ pushd -n .. -
popd argumentos diretorioRemove o diretório no topo da pilha de diretórios e navega até ele.
O exemplo abaixo acessa o diretório no topo na pilha de diretórios armazenado no exemplo acima.
username@hostname:~$ popdE produz a saída
username@hostname:/home$ -
dirsMostra a pilha de diretórios lembrados — que foram adicionados usando o comando
pushd. Alguns argumentos importantes são-cque remove todos os diretórios na pilha;-pque mostra cada diretório por linha e-vque é como o-p, mas ele também enumera!
Manipulando arquivos
Uma das mais poderosas aplicações da linha de comando é o gerenciamento de arquivos. Podemos manipular a identidade do arquivo (buscando-o, movendo-o, copiando-o, deletando-o, etc) e o conteúdo do arquivo (buscando e substituindo padrões, enumerando caracteres, juntando arquivos, etc). Por conta disso, dividiremos essa sessão em Arquivo e Conteúdo.
Arquivo
Considere um cenário em que você precisa documentar um projeto que será
adicionado em um repositório de código do seu novo projeto de software livre.
Um tipo de arquivo comumente utilizado nesse cenário é o README.md. Precisamos
então criar este arquivo.
Uma forma de criar o arquivo é escrever um conteúdo diretamente em um editor de texto de linha de comando e salvá-lo com o nome de um arquivo ainda não existente. Essa opção fará mais sentido quando passarmos para a segunda parte desta seção.
Vamos criar um arquivo inicialmente sem conteúdo algum. Neste caso, podemos
utilizar o comando touch (tocar, em português), como mostrado a seguir.
touch README.mdListe os arquivos do diretório atual após o comando para certificar que ele foi
realmente criado. Outra operação importante é mover ele. Consideramos que, por
algum motivo, queremos colocá-lo na pasta docs dentro da pasta atual,
podemos usar o comando mv para realizar a tarefa da seguinte maneira
mv README.md docsOutra forma é passar também um nome para o arquivo de destino. Assim, fazemos duas operações em uma: mover e renomear. Por exemplo, poderíamos fazer algo como
mv README.md docs/README.txtAssim, o mv também serve para simplesmente renomear arquivos. Basta movê-los
para o mesmo diretório, mas com outros nomes.
Com uma sintaxe bem parecida, podemos copiar um arquivo com o comando cp.
Experimente copiar o arquivo docs/README.md de volta para pasta atual. O cp
também serve para copiar pasta por completo também, bastando dizer para ser
executado recursivamente com o argumento --recursive (-r).
Também de forma muito parecida podemos excluir um arquivo com o comando rm.
Quando executado sem o modo recursivo, rm só apaga arquivos. Utilizando o modo
recursivo (-r), porém tudo tentará ser apagado diretamente.
rm -r, já que não haverá pedido de confirmação. Utilizar o argumento --force (-f) pode tornar as coisas ainda mais catastróficas, já que tudo que for possível será apagado.
Conteúdo
Para a edição do conteúdo de algum arquivo, há bastante limitações, já que cada tipo de arquivo
tem sua melhor forma de ser editado, por exemplo, como editariamos um arquivo .jpg utilizando
um editor de texto? Portanto, vamos focar apenas em arquivos de texto.
Para editar arquivos de texto utilizamos, isso mesmo, um editor de textos! O que vem por padrão
na maioria das distribuições é o nano. Para editar um arquivo com ele, basta digitar
nano nome_do_arquivo, e seu terminal se transformará num editor de texto! Os comandos para salvar,
sair, entre outros estão na parte de baixo do editor, e o caractere ^ significa a tecla Control
do teclado.
Vi instalado, mas não sua versão melhorada, o Vim — Vi improved — entretanto, os dois são bastante similares.
Mudando permissões de arquivos
Como mencionamos brevemente nas responsabilidades do kernel, uma preocupação
importantíssima é a segurança do sistema. No sistema de arquivos, isso é
refletido principalmente pelo esquema de permissões de arquivos (e diretórios).
Para visualizar algumas permissões, vamos continuar utilizando o arquivo
README.md criado anteriormente. Para isso, entre no diretório que ele está e
use o argumento -l do comando ls. Como saída, será gerado algo como
-rw-rw-r-- 1 username usergroup 0 jun 3 10:30 README.mdOs primeiros caracteres indicam justamente a permissão do arquivo. Ignorando o
primeiro caractere, que indica o tipo do registro no sistema de arquivo, temos
três partes de três caracteres, isto é rw-, rw- e r--. Ele são chamado
coletivamente de modos do arquivo. A primeira parte indica as permissões do seu
usuário. O r indica que seu usuário tem a permissão de ler (read, em inglês)
o arquivo, escrever (write) e não tem a permissão de executar (simbolizado por
x quando permitido) o arquivo. A segunda parte indica as permissões do grupo
do seu usuário (neste caso, o grupo é seu user name e só contém seu próprio
usuário). Por fim, a última parte indica as permissões de qualquer usuário, que
neste caso não possui permissão de escrita.
Podemos mudar essas permissões por meio do comando chmod (abreviação de
change mode ou mudar modo). Neste caso, passamos qual é o novo modo de cada
parte. Para uma delas, vamos utilizar um caractere para indicar o nível de
permissão, dentre usuário (u), grupo (g) e outro (o), seguido de um = e
as permissões que queremos configurar utilizando os caracteres rwx. Para
juntar cada nível, separamos por vírgula. Por exemplo, para mudar as permissões
para rwx, r-- e ---, usamos
username@hostname:~$ chmod u=rwx,g=r,o= README.mdVerifique o resultado novamente com o ls -l.
chmod é o chown (abreviação de_change owner_), que muda o dono do arquivo.
Comandando seu sistema
Também podemos comandar nosso sistema usando a linha de comando do terminal! Nessa sessão iremos estudar os comandos que alteram o status de atividade de nossa máquina.
-
shutdown argumentos tempo mensagemO comando
shutdownatua desligando a máquina em um determinado tempo. Seus argumentos mais utilizados são-rque, ao invés de desligar, reinicia seu sistema e-cque cancela algum desligamento agendado. Para agendar um desligamento, basta passar o tempo que você deseja desligar. O argumento+magenda um desligamento para daquimminutos. A palavranowreferencia o tempo 0, portantosudo shutdown nowinicia o desligamento do seu computador imediatamente.O exemplo abaixo agenda um desligamento para meia noite.
username@hostname:~$ sudo shutdown 00:00O comandoshutdownprecisa do prefixosudopara ser executado. -
exitO comando
exitatua encerrando a shell que você se encontra.O exemplo abaixo encerra uma janela de terminal aberta.
username@hostname:~$ exit
Gerenciando processos
Uma outra grande utilidade do uso da linha de comando é para manipular os processos (isto é, programas em execução) da sua máquina. Isso possibilita, por exemplo, que você aniquile um programa travado de uma forma simples, como veremos.
Na primeira parte desta seção, veremos manipulação de processos em execução no sistema no geral e na segunda parte processos especificamente sendo executados na instância atual da bash (isto é, seus processos filhos).
Processos do sistema
Primeiramente, uma funcionalidade esperada é ter uma forma de saber quais são os
processos que estão sendo e informações associadas. Um desses comandos é top,
que mostra de forma dinâmica os processos em execução, além de algumas
informações de consumo de recursos (CPU e memória).
O ps, por outro lado, captura no instante de sua execução a lista de
processos. Alguns argumentos úteis são o -e (lista todos os processos) e -f
(formata com mais informações).
Podemos então combiná-lo com o grep para achar um processo em específico. Por
exemplo, para achar o navegador (supondo que seja o Firefox), podemos executar
username@hostname:~$ ps -e | grep firefoxo que gerará um output parecido com
2169 ? 00:18:52 firefoxO primeiro valor mostrado na linha da saída (2169, neste caso) é o chamado
identificador do processo (process identifier, em inglês), que é abreviado por
PID. Por meio dele, podemos dizer qual processo gostaríamos de parar, por
exemplo.
Para ilustrar justamente isso, abra o explorador de arquivos pela interface
gráfica. No GNOME, o explorador de arquivos possui o nome de nautilus. Assim,
para descobrir o número do processo devemos executar o seguinte comando.
username@hostname:~$ ps -e | grep nautilusSupondo que o PID seja 22752, podemos então encerrar forçadamente o explorador
de arquivos por meio do comando
username@hostname:~$ kill -9 22752O argumento -9 indica que será enviado o sinal SIGKILL ao(s) processo(s)
listados na sequência.
kill em um processo, uma vez que não é solicitada a confirmação. Você pode perder algum progresso que não esteja salvo na aplicação em questão.
pkill e killall, alguns dos quais aceitam parâmetros com o nome do executável ao invés do PID.
Processos filhos da shell
Até o momento, estivemos executando somente um processo por vez na shell. Porém, é possível ter sob controle diferentes processos em uma mesma instância. Esses processos são chamados de jobs (tarefas, em português).
Para ilustrar como manipular esses jobs, vamos considerar um cenário em que um
editor de arquivos (pelo terminal) está sendo usado. Por exemplo, poderíamos
estar editando (ou criando) um arquivo README.md no diretório atual por meio
do nano.
username@hostname:~$ nano README.mdDurante a edição, pode ser que necessitemos verificar algo nos diretórios ou arquivos. Uma possibilidade é abrir outro terminal e verificar, porém isso pode ser inconveniente em alguns cenários, como em uma conexão SSH. Assim, podemos dizer à bash atual que pause o processo atual (isto é, ele para a execução na instrução atual).
Para fazer isso, basta pressionar as teclas Ctrl + z. Com isso, é gerada a
seguinte saída
Use "fg" to return to nano.
[1]+ Stopped nanoe obtemos novamente a possibilidade de executar comandos na bash. Neste caso,
o processo do nano ganhou (+) o identificador 1 de job. Neste momento,
portanto, poderíamos executar qualquer outro comando no terminal que
desejássemos.
Caso desejemos listar os jobs atuais, usamos o comando de mesmo nome, isto é
username@hostname:~$ jobsque retorna uma saída parecida com o gerada na primeira fez que o projeto é pausado.
Para retomar a execução de um processo temos agora duas opções, basicamente. A
primeira delas é voltar para o estado que estávamos antes de pressionar Ctrl +z. Neste caso, queremos que o processo volte a ficar “na frente” (foreground
em inglês). O comando para realizar isso é o fg. Em um cenário em que vários
jobs estão pausados, precisamos passar também o identificador na hora de
executar o comando. Em nosso cenário do editor de texto, podemos então executar
username@hostname:~$ fg 1em que o 1 é o identificador do nano.
A outra opção é deixar o comando executando por baixo dos panos, isto é, no
background. Para isso usamos o comando bg. No caso de um editor de texto,
não faz sentido a execução em background, já que ele é um comando interativo.
Em outros cenários, porém, pode ser muito útil. Quando o processo é finalizado
no background, seu status muda para concluído na próxima vez que executar
jobs.
Gerenciando pacotes
Uma feature incrível do Linux é que podemos instalar pacotes pela linha de comando de nossa
shell! O gerenciador de pacote costuma variar para cada distribuição e podem também variar
como funcionam. Para isso, utilizamos o comando apt — abreviação de “advanced package tool”
— e utilizamos seus argumentos para especificar se queremos instalar, atualizar ou remover um
pacote.
Os argumentos mais utilizados são:
update: é utilizado para baixar informações novas relacionadas a um pacote.upgrade: é utilizado para instalar todos os upgrades disponíveis de todos os pacotes instalados no sistema.full-upgrade: ele faz a mesma coisa que o upgrade, mas remove os pacotes que atrapalharem a atualização do sistema.install: esse é o mais utilizado, ele instala o pacote.remove: e esse remove.
Caso você queira instalar a linguagem de programação Python, por exemplo, basta você
abrir o seu terminal, digitar sudo apt install python, assim como na shell abaixo.
username@hostname:~$ sudo apt install pythonNunca foi tão fácil, né? :)
sudo! E tome cuidado tentando supor os nomes dos pacotes que você quer instalar! Talvez instale um pacote indesejado.
Abrindo aplicações gráficas
Algumas aplicações podem ser abertas diretamente pela shell, nesse caso, a shell inteira será utilizada para continuar rodando esse aplicativo, com base nisso, a seção Gerenciando Processos pode ajudar bastante a lidar com esse cenário! Algumas dessas aplicações são:
firefox: o navegador de internet.code: o editor de código Visual Code.nautilus: o gerenciador de arquivos do Ubuntu (e de outras distros).
Com isso, basta você digitar o nome do aplicativo e ele começa a rodar, abrindo uma interface gráfica normalmente, como se você tivesse aberto do seu menu de aplicações. Por exemplo, caso você queira abrir o Visual Code para programar um arquivo em Python mas quer fazer isso dentro de um novo diretório chamado src, você pode digitar o comando
username@hostname:~$ code src/script.pyOutro comando bastante útil nesse caso é o xdg-open que abre qualquer arquivo passado no parâmetro
na aplicação de preferência do usuário. Por exemplo:
Caso você queira abrir um arquivo .html, uma página da web, no seu navegador pelo terminal, você pode
digitar o comando
username@hostname:~$ xdg-open index.htmlUtilizando TeleTypewriter (TTY)
Durante toda a aula, utilizamos o terminal para a execução dos comandos. O terminal é um software de interface gráfica do ambiente de Desktop utilizado. Porém, existe também a possibilidade de interagir com a linha de comando por outro mecanismo, que não depende do ambiente do Desktop: o TeleTypewriter (TTY).
Quando o sistema é iniciado, vários TTY são criados e são identificados por
números. Para acessar o TTY 3, basta pressionar conjuntamente as teclas Ctrl + Alt + F3. Para retornar à interface gráfica, pressione Ctrl + Alt + F2. Os
outros TTY podem ser acessados com o mesmo atalho, mas variando a numeração da
tecla F utilizada.
Uma vez em um TTY, é possível realizar login e ter acesso a um bash. Nele, você pode executar tudo que aprendeu nesta aula sem depender da interface gráfica do sistema.
Como esta aula tem muitos conceitos e novidades, não hesite em revisitá-la daqui um tempo para absorver um pouco mais do que foi exposto.
Isso conclui a segunda parte do Curso de Linux. Até semana que vem! 🐧